Optimisation des tokens Claude : maîtrisez votre contexte
L'essentiel à retenir : l'optimisation des tokens repose sur une gestion stricte de l'historique pour stopper le gaspillage. Utilisez impérativement les commandes /clear et /compact pour réinitialiser le contexte et divisez vos documents volumineux. Ce workflow préserve votre quota, booste la précision et réduit vos coûts de 80% en privilégiant le modèle Haiku pour les tâches simples !
Saviez-vous que Claude 2.1 peut traiter jusqu'à 200 000 tokens, soit l'équivalent de 500 pages de texte en une seule fois ?
Pourtant, sans une gestion rigoureuse de votre historique, cette fenêtre de contexte explose et sature vos sessions à une vitesse fulgurante. Je vais vous montrer comment restructurer radicalement vos échanges et optimiser l'utilisation des tokens sur Claude pour diviser votre consommation par dix et booster vos performances immédiatement.
Sommaire
- Optimisation des tokens Claude : pourquoi votre session sature
- 9 pièges qui siphonnent vos jetons inutilement
- Architecture Tiered Context pour alléger la charge
- Comment piloter sa consommation en temps réel ?
- Workflow intelligent : moins de bruit, plus d'impact
Optimisation des tokens Claude : pourquoi votre session sature
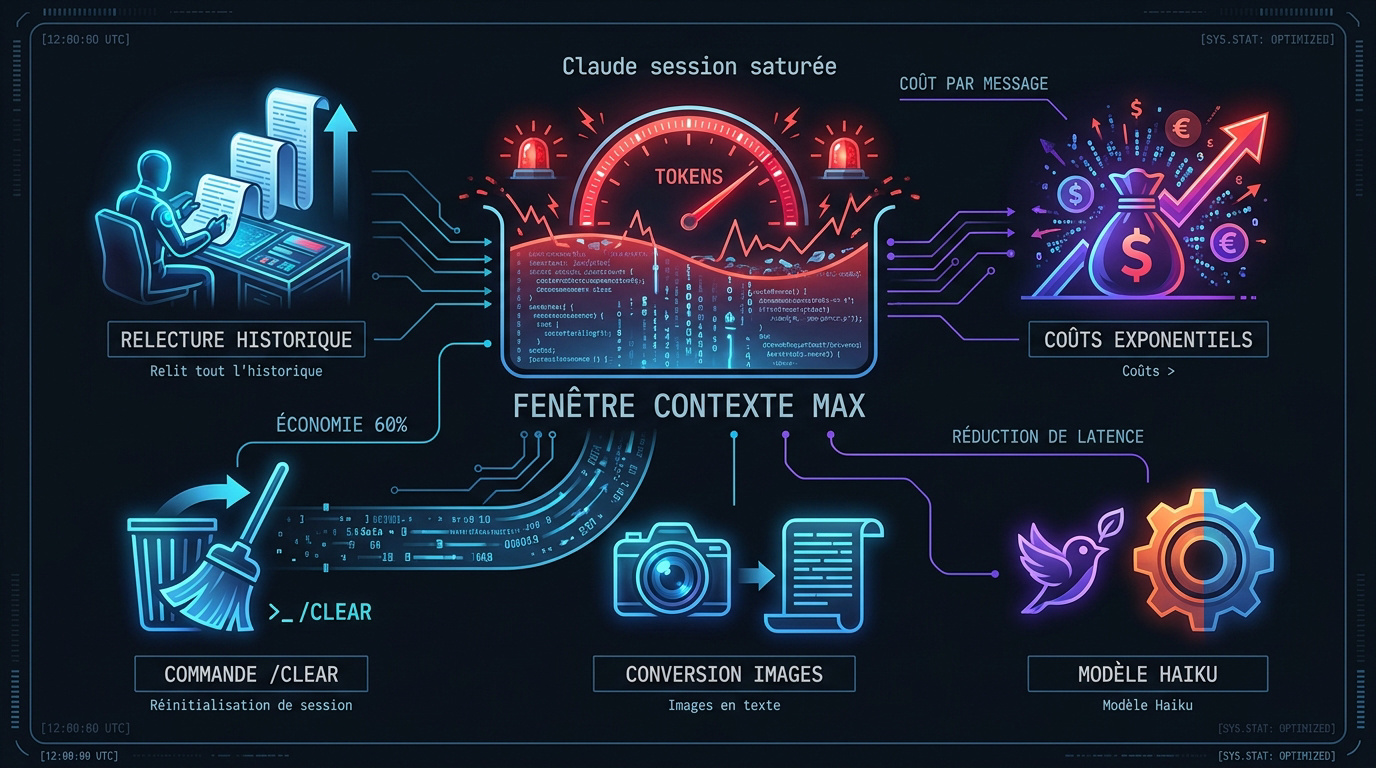
Une session sature car Claude relit l'intégralité de l'historique à chaque message, augmentant les coûts exponentiellement. L'usage de /clear, la conversion des images et le choix du modèle Haiku réduisent la consommation de 60% — des leviers techniques qui préservent la fenêtre de contexte.
On va pas se mentir : comprendre la mécanique entre quota de messages et jetons est le premier pas pour dompter la bête et ne plus rester bloqué en plein travail.
Tokens vs messages : la mécanique du contexte
Le quota de messages est une simple barrière commerciale. À l'inverse, la fenêtre de contexte représente la limite technique de mémoire de l'IA.
Chaque nouvel envoi force Claude à mouliner à nouveau tous les mots précédents. Ce processus sature l'espace de calcul disponible à une vitesse folle. Vous voyez le problème ?
Les LLM n'ont aucune mémoire intrinsèque. Allez jeter un œil à ce guide sur l'optimisation des tokens pour comprendre pourquoi vous brûlez votre budget inutilement.
L'effet boule de neige des fils de discussion
Plus votre discussion s'étire, plus le coût par message explose de façon invisible. C'est mathématique : le poids des données s'accumule et finit par peser lourd.
Cet historique massif crée une latence insupportable. Les réponses deviennent lentes et Claude perd de sa superbe précision habituelle. Frustrant, non ?
Chaque message envoyé à Claude force le modèle à relire l'intégralité de l'historique de la conversation, entraînant une augmentation exponentielle des coûts en tokens.
Bref, segmentez vos tâches. Garder un contexte propre est le secret pour rester productif toute la journée.
9 pièges qui siphonnent vos jetons inutilement
Au-delà de la structure des échanges, certains éléments de contenu agissent comme de véritables gouffres à jetons.
Fichiers obèses et réponses verbeuses
Attention à vos visuels. Une simple capture d'écran peut engloutir autant de tokens que des milliers de mots bruts. C'est un gouffre financier silencieux.
Utilisez le plugin Caveman. Cet outil génial force Claude à la concision extrême. Il sabre les tokens de sortie inutiles sans sacrifier la précision technique.
- Images pesant 20x plus que le texte brut.
- PDF non compressés transformés en images coûteuses.
- Logs bruts interminables saturant le contexte.
- Politesses excessives de l'IA qui rallongent la facture.
Soyez malins. Convertissez systématiquement vos fichiers lourds en texte simple avant l'importation. Votre portefeuille vous remerciera.
Erreurs de modèle et surcharge de configuration
Arrêtez de gaspiller Opus. Utiliser ce modèle surpuissant pour des tâches basiques est une hérésie technique. C'est jeter de l'argent par les fenêtres.
Surveillez votre fichier Claude.md. S'il est trop chargé, il dévore une part fixe de votre contexte. Chaque interaction devient alors inutilement lourde.
Nettoyez vos serveurs MCP. Charger des outils inutilisés alourdit le prompt système. Cela ralentit tout sans apporter le moindre bénéfice réel.
Comparez avec Gemini 3.1 Pro pour voir comment d'autres modèles gèrent ces capacités de raisonnement. Choisissez toujours l'outil adapté au besoin.
Architecture Tiered Context pour alléger la charge
Pour contrer ces gaspillages, une organisation rigoureuse de l'information permet de ne charger que le strict nécessaire.
Hiérarchiser l'information avec la documentation par niveaux
Le Tiered Context change tout. On sépare les connaissances critiques des détails secondaires. C'est la clé pour optimiser votre mémoire de session.
| Niveau | Type de contenu | Fréquence de chargement |
|---|---|---|
| Niveau 1 (Core Docs) | Systématique | Haute |
| Niveau 2 (Spécifications) | Sur demande | Moyenne |
| Niveau 3 (Logs/Détails) | Rarement | Basse |
Allez voir ce dépôt GitHub. Il prouve qu'on peut réduire l'usage des tokens de 87% avec cette structure.
Cette méthode est redoutable. Elle libère des milliers de jetons. Vous gardez enfin de la place pour le travail réel.
Automatiser le nettoyage via des hooks de session
Découvrez le script session-start.sh. Ce petit outil automatise le filtrage du contexte. Tout se joue dès l'ouverture de votre session.
La compaction automatique est votre alliée. Résumer les échanges passés conserve l'essentiel. On ne traîne plus tout l'historique verbeux et inutile.
Les économies sont massives. Cette approche réduit les tokens chargés de 62%. Les analyses techniques récentes confirment ce gain de performance incroyable.
Vous voulez passer au niveau supérieur ? Utilisez Claude Desktop. C'est parfait pour automatiser ses tâches localement et gagner en efficacité.
Comment piloter sa consommation en temps réel ?
Une fois l'architecture en place, il faut apprendre à surveiller ses jauges pour ne jamais être pris de court.
Maîtriser les commandes natives /usage et /compact
Utilisez la commande /usage. Elle permet de voir instantanément le volume de jetons consommés dans la session actuelle. C'est l'outil parfait pour garder un œil sur votre budget.
Expliquez /clear et /compact. Ces commandes réinitialisent la mémoire vive de l'agent sans perdre le fil du projet en cours. C'est magique pour alléger le contexte sans tout casser. On adore !
- /usage pour le diagnostic
- /compact pour résumer
- /clear pour repartir à zéro
- /context pour vérifier les fichiers
Mise en place d'une status line visuelle
Créer un indicateur visuel. Une ligne de statut permet de suivre sa consommation sans avoir à taper de commandes. C'est un gain de temps monstrueux pour rester concentré.
Anticiper les limites TPM et RPM. En équipe, cette visibilité évite de bloquer les collègues par une surconsommation soudaine. Personne ne veut être celui qui paralyse tout le service, n'est-ce pas ?
Besoin de plus de puissance ? Jetez un œil à ces Outils SEO pour découvrir d'autres solutions de monitoring. Cet article explique comment optimiser l'utilisation des tokens sur Claude pour éviter d'atteindre rapidement la limite de session.
Workflow intelligent : moins de bruit, plus d'impact
Enfin, l'efficacité maximale repose sur un réglage fin du comportement de l'IA et de vos propres prompts.
Ajuster le mode thinking et les sous-agents
Configurez votre paramètre MAX_THINKING_TOKENS. Limiter la réflexion interne à 10 000 jetons suffit amplement. Cela règle les problèmes complexes sans gaspiller votre quota inutilement.
Arbitrez intelligemment entre vos agents. Utiliser le modèle Haiku pour les sous-agents de lecture est un pur coup de génie. Vous réduisez vos coûts de 80% comparé à Sonnet.
"L'utilisation de Haiku pour les sous-agents est conseillée, car ils sont 80% moins chers et suffisants pour l'exploration de fichiers."
Prétraitement des fichiers et prompt engineering
Nettoyez tout avant l'importation. Supprimez les lignes redondantes de vos logs. Vous économiserez ainsi un contexte précieux pour les analyses réellement importantes.
Optimisez vos instructions de projet. Des consignes ultra précises réduisent les allers-retours fatigants. C'est la clé pour préserver votre quota de messages quotidien sans effort.
Testez une approche différente comme Rédiger Sans Migraine pour varier vos méthodes. Cet article explique comment optimiser l'utilisation des tokens sur Claude pour éviter d'atteindre rapidement la limite de session.
Maîtrisez dès maintenant votre consommation en segmentant vos fichiers et en utilisant les commandes /compact ou /clear pour réinitialiser votre contexte. Cette optimisation stratégique des jetons libère 90% de votre fenêtre de travail pour des résultats foudroyants. Dominez l'IA, économisez vos ressources et propulsez votre productivité vers de nouveaux sommets !


